A Database and a Database Management System (DBMS) are closely related terms, but they serve different purposes:
A database is a structured set of data. The data can be structured or unstructured and stored in various formats like tables, documents, and key-value pairs. It could be anything from a simple shopping list to a picture gallery or the vast amount of information in a corporate network.
A DBMS (Database Management System) is software used to interact with a database. It provides an interface for users or applications to manipulate data, making the handling of large amounts of data more efficient and less error-prone. A DBMS oversees core administrative tasks such as data storage, retrieval, security, concurrency control, backup and recovery, and query processing. Examples include Oracle Database, MySQL, Microsoft SQL Server, and MongoDB.
In simpler terms, a database is like a container that holds the information, while a DBMS is a tool used to organize and manage the contents within that container.
To make things a little bit more complicated, the term “database” is often used informally to denote the DBMS, the database system, or even an application connected to the database. Moving forward, we will refer to the Database Management System (DBMS) as the “database,” while the actual data stored will be referred to simply as “data.”
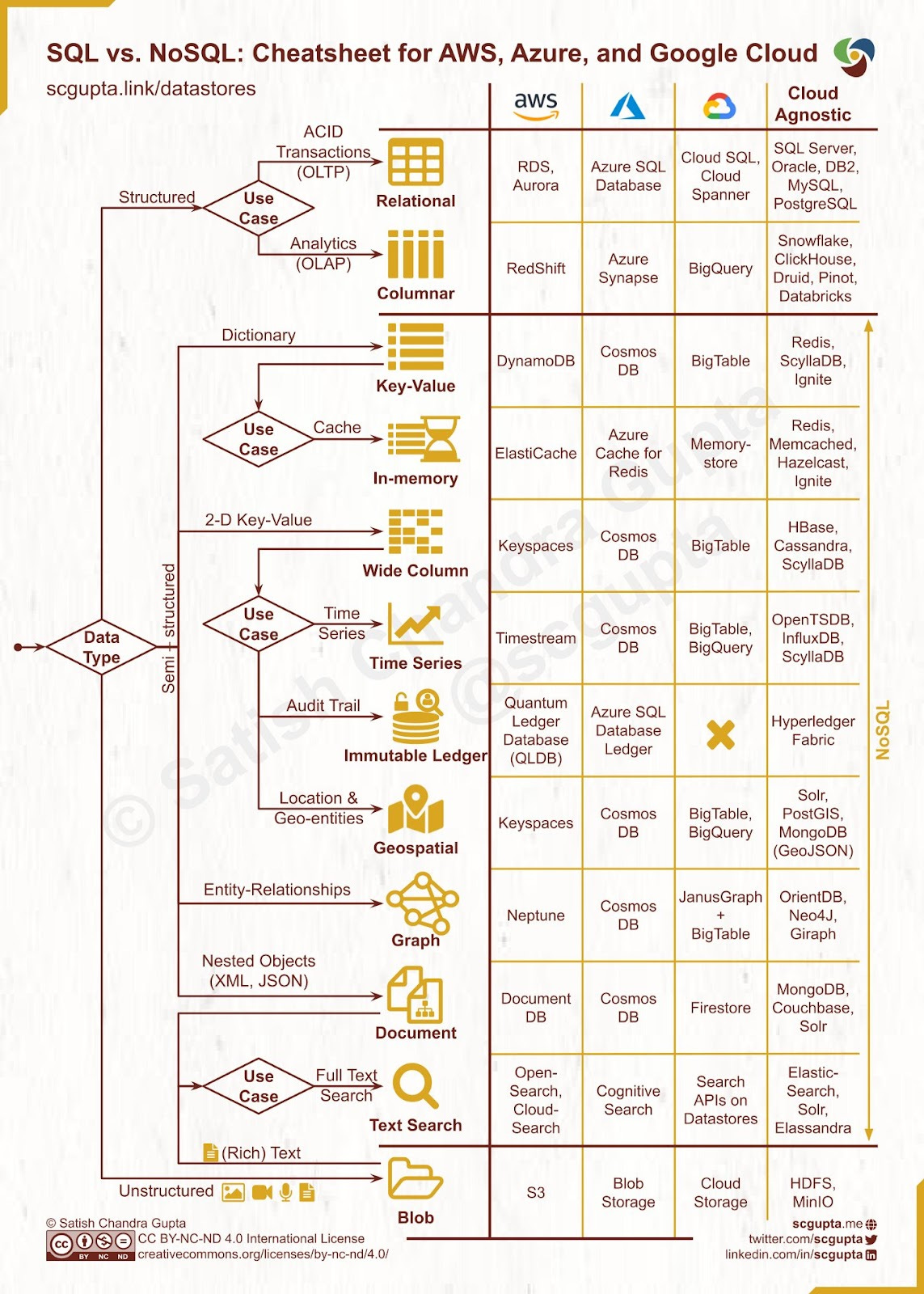
database types
Hierarchical Databases
Developed in the 1960s, the hierarchical database looks similar to a family tree. A single object (the “parent”) has one or more objects beneath it (the “child”). No child can have more than one parent. In exchange for the rigid and complex navigation of the parent child structure, the hierarchical database offers high performance, as there’s easy access and a quick querying time. The Windows Registry is one example of this system.
Relational Databases
Relational databases are a system designed in the 1970s. This database commonly uses Structured Query Language (SQL) for operations like creating, reading, updating, and deleting (CRUD) data.
This database stores data in discrete tables, which can be joined together by fields known as foreign keys. For example, you might have a User table that contains data about your users, and join the users table to a Purchases table, which contains data about the purchases the users have made. MySQL, Microsoft SQL Server, and Oracle are examples.
Non-Relational Databases
Non-relational management systems are commonly referred to as NoSQL databases. This type of database matured due to increasingly complex modern web applications. These databases' varieties have proliferated over the last decade. Examples include MongoDB and Redis.
Object oriented databases
Object oriented databases store and manage objects on a database server's disk. Object oriented databases are unique because associations between objects can persist. This means that object oriented programming and the querying of data across complex relationships is fast and powerful. One example of an object oriented database is MongoDB Realm, where the query language constructs native objects through your chosen SDK. Object oriented programming is the most popular programming paradigm.
All about NoSQL
NoSQL is an umbrella term for any alternative system to traditional SQL databases. Sometimes, when we say NoSQL management systems, we mean any database that doesn't use a relational model. NoSQL databases use a data model that has a different structure than the rows and columns table structure used with RDBMS.
NoSQL databases are different from each other. There are four kinds of this database: document databases, key-value stores, column-oriented databases, and graph databases.
Document databases
A document database stores data in JSON, BSON, or XML documents. Documents in the database can be nested. Particular elements can be indexed for faster querying.
You can access, store, and retrieve documents from your network in a form that is much closer to the data objects used in applications, which means less translation is required to use and access the data in an application. SQL data must often be assembled and disassembled when moving between applications, storage, or more than one network.
Document databases are popular with developers because they offer the flexibility to rework their document structures as needed to suit their applications. The flexibility of this database speeds development — data becomes like code and is under the control of developers. They can more easily access and use it. In SQL databases, intervention by database administrators may be required to change the structure of a database.
Document databases are usually implemented with a scale-out architecture, providing a path to the scalability of data volumes and traffic. Use cases include eCommerce platforms, trading platforms, and mobile app development.
Comparing MongoDB vs. PostgreSQL offers an analysis of MongoDB, the leading distributed NoSQL database, and PostgreSQL (an open source DBMS). Unlike a centralized database, it exists on multiple databases but presents as one.
Key-value stores
This is the simplest type of NoSQL database. Every element is stored as a key-value pair consisting of an attribute name ("key") and a value. This database is like an RDBMS with two columns: the attribute name (such as "state") and the value (such as "Alaska").
Use cases for NoSQL databases include shopping carts, user preferences, and user profiles.
Column-oriented databases
While an RDBMS stores data in rows and reads it row by row, column-oriented databases are organized as a set of columns. When you want to run analytics on a small number of columns in the network, you can read those columns directly without consuming memory with unwanted data. Columns are of the same type and benefit from more efficient compression, making reads even faster. A column-oriented database can aggregate the value of a given column (adding up sales for the year, for example). Use cases of a column-oriented database include analytics.
While column-oriented databases are great for analytics, the way they write data makes it difficult for them to be consistent as writes of all the columns in the column-oriented database require multiple write events on disk. Relational databases don't suffer from this problem as row data is written contiguously to disk.
Graph databases
A graph database focuses on the relationship between data elements. Each element is contained as a node. The connections between elements in the database are called links or relationships. Connections are first-class elements of the database, stored directly.
A graph database is optimized to capture and search the connections between elements, overcoming the overhead associated with JOINing several tables in SQL. Very few real-world business systems can survive solely on graph databases. As a result, graph databases are usually run alongside more traditional databases.
Use cases include fraud detection and social networks.
These databases are diverse in their data formats and applications. Furthermore, systems store data in different ways:
Data can be stored in a structured document, similar to JSON (JavaScript Object Notation). MongoDB is a popular document distributed database.
Data can be in a key-value format that maps a single attribute (key) to its value. Redis and Riak KV are examples. They’re typically used for simple one-to-one relationships, like associating users with preferences.
A graph datastore uses nodes to represent objects and edges to describe the relationship between them. Neo4j is one example.
These differ from RDBMS in that they can be schema-agnostic, allowing unstructured and semi-structured data in a network to be stored and processed.
CDN stands for Content Delivery Network. It is a distributed network of servers located geographically closer to users, designed to deliver web content and assets (such as images, videos, stylesheets, scripts, etc.) more efficiently. The main purpose of a CDN is to reduce latency and improve the performance of websites and web applications by serving content from servers that are physically closer to the user's location.
How CDN Works:
Content Distribution: When a user requests content from a website or application, such as loading a webpage, the request is routed to the nearest CDN server instead of the origin server where the content is hosted.
Server Selection: The CDN server delivers the content to the user based on various factors such as server load, proximity to the user, and current network conditions. This helps in reducing the time it takes for content to reach the user (reducing latency).
Caching: CDNs cache content at their edge servers strategically placed around the globe. This means that frequently accessed content (like images or stylesheets) can be delivered more quickly because it is already stored closer to the user's location.
Load Balancing: CDNs often employ load balancing techniques to distribute incoming requests across multiple servers, ensuring optimal performance and reliability even during high traffic periods or unexpected surges.
Benefits of CDN:
Improved Website Performance: Reduced latency and faster content delivery speed up website loading times, improving user experience and satisfaction.
Scalability: CDNs help websites handle large volumes of traffic more effectively by offloading the origin server and distributing the load across multiple edge servers.
Global Reach: By having servers located worldwide, CDNs ensure consistent performance for users across different geographic locations.
Security: Some CDNs offer security features such as DDoS protection, SSL/TLS termination, and web application firewall (WAF) capabilities to protect against various cyber threats.
Common Uses of CDN:
Static Content Delivery: Serving static assets like images, CSS, JavaScript files, and downloadable files (PDFs, documents).
Streaming Media: Delivering audio and video content through streaming protocols to ensure smooth playback.
API Delivery: Accelerating delivery of API responses, improving responsiveness for web and mobile applications.
Potential disadvantages and considerations:
Cost: Using a CDN typically incurs costs, especially for high-traffic websites or applications that require extensive data transfer. Costs can vary based on data usage, number of requests, and additional features like DDoS protection.
Complexity: Implementing and managing a CDN setup can add complexity to your infrastructure. It may require configuration changes, DNS adjustments, and monitoring to ensure optimal performance and reliability.
Cache Invalidation: Cached content on CDN servers may need to be invalidated or refreshed when updates are made to your origin server. Managing cache invalidation can be challenging, and stale content could potentially be served to users.
Data Privacy: Depending on the CDN provider and service level, there may be concerns about data privacy and security. Ensure that your CDN provider adheres to necessary compliance and security standards, especially for sensitive data.
Dependency on Provider: Relying on a third-party CDN provider means your website's performance and availability are partly dependent on their infrastructure and service reliability. Downtimes or outages from the CDN provider could impact your website's accessibility.
Potential for Overhead: In some cases, using a CDN may introduce additional overhead due to the need for content replication, caching logic, and network routing. This overhead can affect the initial setup and ongoing maintenance of your CDN setup.
Regulatory Compliance: Depending on your industry and geographical location, there may be regulatory requirements regarding data storage, transfer, and privacy that need to be considered when using a CDN, especially for global content delivery.
Mitigating Disadvantages:
Cost Management: Evaluate CDN pricing plans based on your traffic patterns and needs. Monitor usage and optimize content delivery strategies to minimize costs.
Configuration and Monitoring: Implement robust monitoring and management practices to handle CDN configuration changes, cache invalidation, and performance optimization.
Data Security: Choose a CDN provider that offers strong security features and compliance with data protection regulations. Implement additional security measures as necessary to protect sensitive data.
Redundancy and Failover: Consider implementing multi-CDN strategies or failover mechanisms to mitigate risks associated with CDN downtime or outages.
In conclusion, while CDNs offer significant benefits in terms of performance, scalability, and global reach, it's important to carefully assess potential drawbacks and plan accordingly to maximize the advantages while mitigating risks.