A Database and a Database Management System (DBMS) are closely related terms, but they serve different purposes:
A database is a structured set of data. The data can be structured or unstructured and stored in various formats like tables, documents, and key-value pairs. It could be anything from a simple shopping list to a picture gallery or the vast amount of information in a corporate network.
A DBMS (Database Management System) is software used to interact with a database. It provides an interface for users or applications to manipulate data, making the handling of large amounts of data more efficient and less error-prone. A DBMS oversees core administrative tasks such as data storage, retrieval, security, concurrency control, backup and recovery, and query processing. Examples include Oracle Database, MySQL, Microsoft SQL Server, and MongoDB.
In simpler terms, a database is like a container that holds the information, while a DBMS is a tool used to organize and manage the contents within that container.
To make things a little bit more complicated, the term “database” is often used informally to denote the DBMS, the database system, or even an application connected to the database. Moving forward, we will refer to the Database Management System (DBMS) as the “database,” while the actual data stored will be referred to simply as “data.”
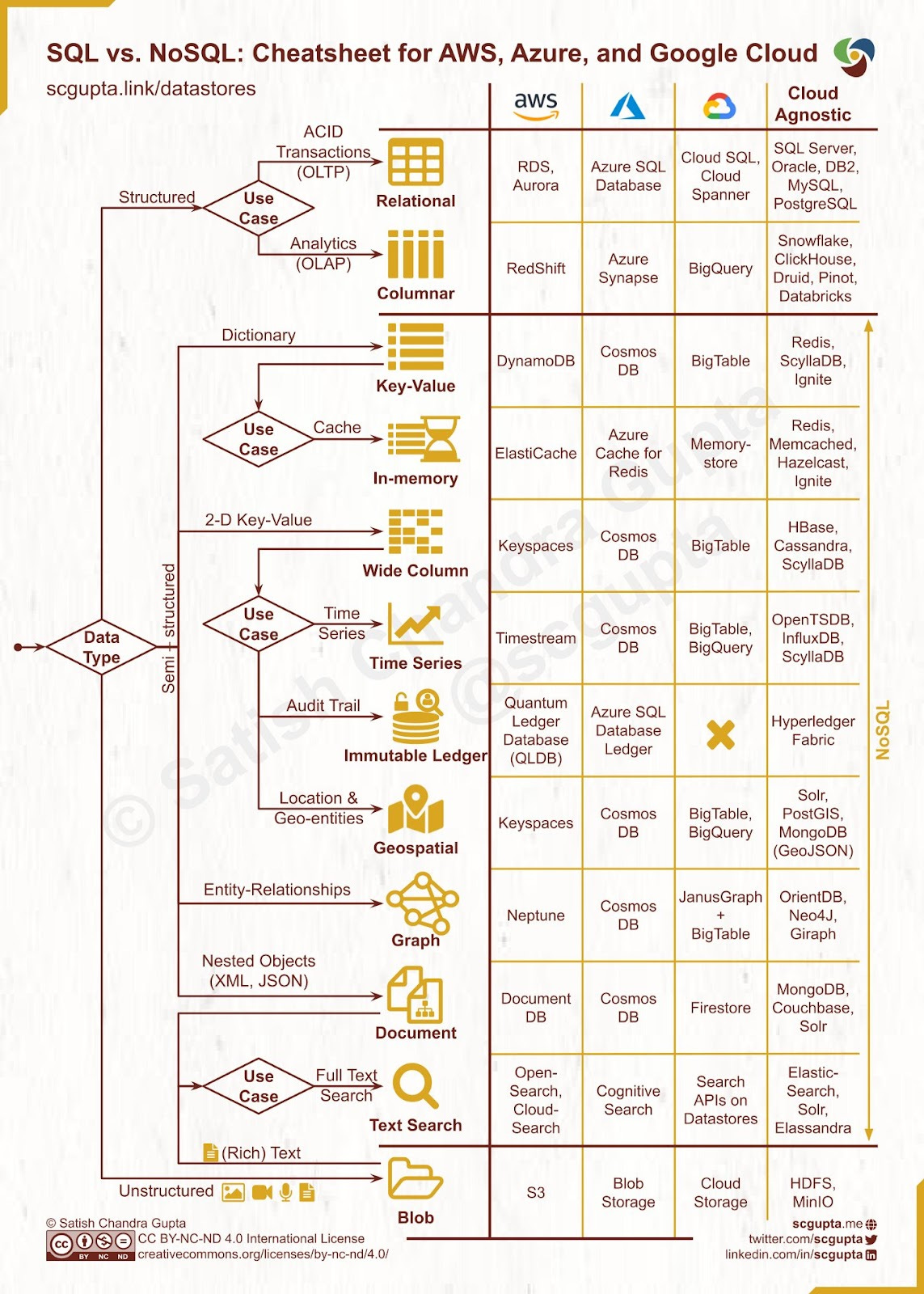
database types
Hierarchical Databases
Developed in the 1960s, the hierarchical database looks similar to a family tree. A single object (the “parent”) has one or more objects beneath it (the “child”). No child can have more than one parent. In exchange for the rigid and complex navigation of the parent child structure, the hierarchical database offers high performance, as there’s easy access and a quick querying time. The Windows Registry is one example of this system.
Relational Databases
Relational databases are a system designed in the 1970s. This database commonly uses Structured Query Language (SQL) for operations like creating, reading, updating, and deleting (CRUD) data.
This database stores data in discrete tables, which can be joined together by fields known as foreign keys. For example, you might have a User table that contains data about your users, and join the users table to a Purchases table, which contains data about the purchases the users have made. MySQL, Microsoft SQL Server, and Oracle are examples.
Non-Relational Databases
Non-relational management systems are commonly referred to as NoSQL databases. This type of database matured due to increasingly complex modern web applications. These databases' varieties have proliferated over the last decade. Examples include MongoDB and Redis.
Object oriented databases
Object oriented databases store and manage objects on a database server's disk. Object oriented databases are unique because associations between objects can persist. This means that object oriented programming and the querying of data across complex relationships is fast and powerful. One example of an object oriented database is MongoDB Realm, where the query language constructs native objects through your chosen SDK. Object oriented programming is the most popular programming paradigm.
All about NoSQL
NoSQL is an umbrella term for any alternative system to traditional SQL databases. Sometimes, when we say NoSQL management systems, we mean any database that doesn't use a relational model. NoSQL databases use a data model that has a different structure than the rows and columns table structure used with RDBMS.
NoSQL databases are different from each other. There are four kinds of this database: document databases, key-value stores, column-oriented databases, and graph databases.
Document databases
A document database stores data in JSON, BSON, or XML documents. Documents in the database can be nested. Particular elements can be indexed for faster querying.
You can access, store, and retrieve documents from your network in a form that is much closer to the data objects used in applications, which means less translation is required to use and access the data in an application. SQL data must often be assembled and disassembled when moving between applications, storage, or more than one network.
Document databases are popular with developers because they offer the flexibility to rework their document structures as needed to suit their applications. The flexibility of this database speeds development — data becomes like code and is under the control of developers. They can more easily access and use it. In SQL databases, intervention by database administrators may be required to change the structure of a database.
Document databases are usually implemented with a scale-out architecture, providing a path to the scalability of data volumes and traffic. Use cases include eCommerce platforms, trading platforms, and mobile app development.
Comparing MongoDB vs. PostgreSQL offers an analysis of MongoDB, the leading distributed NoSQL database, and PostgreSQL (an open source DBMS). Unlike a centralized database, it exists on multiple databases but presents as one.
Key-value stores
This is the simplest type of NoSQL database. Every element is stored as a key-value pair consisting of an attribute name ("key") and a value. This database is like an RDBMS with two columns: the attribute name (such as "state") and the value (such as "Alaska").
Use cases for NoSQL databases include shopping carts, user preferences, and user profiles.
Column-oriented databases
While an RDBMS stores data in rows and reads it row by row, column-oriented databases are organized as a set of columns. When you want to run analytics on a small number of columns in the network, you can read those columns directly without consuming memory with unwanted data. Columns are of the same type and benefit from more efficient compression, making reads even faster. A column-oriented database can aggregate the value of a given column (adding up sales for the year, for example). Use cases of a column-oriented database include analytics.
While column-oriented databases are great for analytics, the way they write data makes it difficult for them to be consistent as writes of all the columns in the column-oriented database require multiple write events on disk. Relational databases don't suffer from this problem as row data is written contiguously to disk.
Graph databases
A graph database focuses on the relationship between data elements. Each element is contained as a node. The connections between elements in the database are called links or relationships. Connections are first-class elements of the database, stored directly.
A graph database is optimized to capture and search the connections between elements, overcoming the overhead associated with JOINing several tables in SQL. Very few real-world business systems can survive solely on graph databases. As a result, graph databases are usually run alongside more traditional databases.
Use cases include fraud detection and social networks.
These databases are diverse in their data formats and applications. Furthermore, systems store data in different ways:
Data can be stored in a structured document, similar to JSON (JavaScript Object Notation). MongoDB is a popular document distributed database.
Data can be in a key-value format that maps a single attribute (key) to its value. Redis and Riak KV are examples. They’re typically used for simple one-to-one relationships, like associating users with preferences.
A graph datastore uses nodes to represent objects and edges to describe the relationship between them. Neo4j is one example.
These differ from RDBMS in that they can be schema-agnostic, allowing unstructured and semi-structured data in a network to be stored and processed.
RavenDB is a NoSQL, open-source, distributed database designed to be scalable, flexible, and easy to use. It is known for its high performance, advanced features, and focus on developer productivity. Here are some key features and use cases of RavenDB:
Key Features
ACID Transactions: RavenDB supports fully ACID-compliant transactions, which is relatively rare in the NoSQL world.
Schema-Free: It is schema-free, allowing for flexible data models and easy evolution of your data structures over time.
Indexing: Automatic indexing and full-text search capabilities make it easy to query and retrieve data.
Replication and Sharding: Supports multi-master replication and sharding, ensuring high availability and scalability.
Built-in Security: Includes built-in security features like SSL, authentication, and authorization.
Graph Queries: Supports graph queries, allowing complex relationships and connections between data to be modeled and queried efficiently.
Time Series and Counters: Has specialized data types for time series and counters, making it suitable for applications requiring time-based data analysis.
Some Use Cases
Real-Time Web Applications:
Example: A social media platform where users interact in real-time, post updates, and respond to events quickly.
Why RavenDB: Fast reads and writes, ACID transactions ensure data integrity, and real-time data processing capabilities.
E-Commerce:
Example: An online store with a high volume of transactions, product catalogs, user reviews, and recommendations.
Why RavenDB: Handles large datasets, provides high availability and quick data retrieval, and can manage complex queries like product recommendations.
IoT and Time Series Data:
Example: An IoT platform collecting sensor data from devices and performing real-time analytics.
Why RavenDB: Time series data type, efficient handling of large volumes of data, and real-time processing capabilities.
Content Management Systems (CMS):
Example: A CMS that stores and manages large amounts of content, such as articles, images, and multimedia.
Why RavenDB: Schema-free nature allows for flexible content models, efficient indexing and search capabilities, and easy scaling.
Finance and Banking:
Example: A banking application handling transactions, user accounts, and financial records.
Why RavenDB: ACID compliance ensures data integrity, high performance for transaction processing, and built-in security features.
Healthcare:
Example: A healthcare system managing patient records, appointment schedules, and medical histories.
Why RavenDB: Schema flexibility for diverse data types, high availability, and strong security measures to protect sensitive data.
Gaming:
Example: An online multiplayer game with player profiles, game states, and leaderboards.
Why RavenDB: Real-time data handling, efficient storage of game states, and scalability to handle many concurrent users.
Advantages
Ease of Use: RavenDB's intuitive interface and developer-friendly features reduce the learning curve.
Performance: Optimized for high performance with fast reads and writes.
Scalability: Easily scales horizontally with replication and sharding.
Security: Robust security features to protect data.
Support: Strong community support and comprehensive documentation.
RavenDB is suitable for a wide range of applications, especially those requiring high performance, flexibility, and scalability. Its combination of NoSQL flexibility with ACID transaction support makes it a powerful choice for modern applications.
RavenDB x Postgresql
RavenDB and PostgreSQL are both powerful databases, but they excel in different areas due to their distinct architectures and design philosophies. Here are some scenarios and features where RavenDB can perform better than PostgreSQL:
Performance and Scalability
Automatic Indexing:
RavenDB: Automatically indexes data and adapts to query patterns without manual intervention, optimizing performance for read-heavy operations.
PostgreSQL: Requires manual index management, which can be time-consuming and complex for developers.
Replication and Sharding:
RavenDB: Built-in support for multi-master replication and automatic sharding, making it easy to scale horizontally across multiple nodes and data centers.
PostgreSQL: Replication and sharding require additional configuration and third-party tools, making it more complex to set up and maintain.
Real-Time Analytics:
RavenDB: Designed for real-time data processing and analytics, with features like built-in full-text search, map/reduce, and graph queries.
PostgreSQL: While capable of handling analytics, it typically requires additional extensions and optimization to achieve similar performance.
Flexibility and Development
Schema-Free:
RavenDB: Schema-free design allows for flexible data models and easy evolution of data structures, which is beneficial for agile development and rapid iteration.
PostgreSQL: Schema changes can be complex and require careful planning to avoid downtime or data migration issues.
Document-Oriented:
RavenDB: As a document-oriented database, it naturally handles complex, hierarchical data structures (e.g., JSON documents) without the need for complex joins.
PostgreSQL: While it supports JSON and JSONB data types, complex hierarchical data often requires intricate queries and optimizations.
Built-In Features
Time Series and Counters:
RavenDB: Provides specialized support for time series data and counters, making it ideal for applications that need to handle time-based data efficiently.
PostgreSQL: Requires additional extensions or complex table structures to handle time series data with similar efficiency.
Security:
RavenDB: Comes with built-in security features such as SSL, authentication, and authorization, simplifying the process of securing your data.
PostgreSQL: Security features are robust but often require more manual configuration and management.