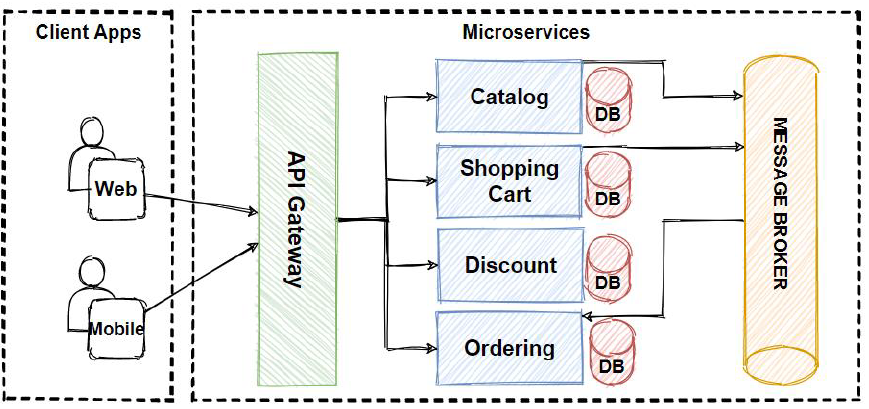
The collection of small services that are combined to form the actual application is the concept of microservices pattern. Instead of building a bigger application, small programs are built for every service (function) of an application independently. And those small programs are bundled together to be a full-fledged application. So adding new features and modifying existing microservices without affecting other microservices are no longer a challenge when an application is built in a microservices pattern. Modules in the application of microservices patterns are loosely coupled. So they are easily understandable, modifiable and scalable.
Advantages:
Scalability: Each service can be scaled independently based on demand.
Faster Delivery: Independent services allows teams to develop, test, and deploy features faster.
Easier Maintenance: Services can be updated and maintained independently.
Event-Driven Architecture is a software design pattern where the production, detection, consumption, and reaction to events is central to the structure and operation of the system. In an EDA, events are the key component driving the flow of information and triggering actions or processes. This contrasts with traditional request-driven architectures where components directly call each other's APIs to initiate actions.
Benefits of Event-Driven Architecture:
Loose Coupling: Components in an EDA are loosely coupled because they interact through events rather than direct method calls. This makes the system more flexible and easier to scale and maintain.
Scalability: EDA supports horizontal scalability well, as components can independently process events without being tightly coupled to each other. This allows for better utilization of resources and handling of varying workloads.
Flexibility and Agility: EDA enables systems to adapt to changes more easily. New functionalities can be added by introducing new event types or subscribers without significantly impacting existing components.
Asynchronous Communication: Events in EDA are typically processed asynchronously, allowing components to operate independently and improve overall system responsiveness.
Decoupled Microservices: EDA is well-suited for microservices architectures, where each microservice can react to events it subscribes to without needing to know about the internal details of other services.
Disadvantages of Event-Driven Architecture:
Complexity in Event Flow: Managing event flows and ensuring proper sequencing of events can be challenging, especially in systems with complex interactions and dependencies.
Event Loss: If not handled properly, events can be lost if subscribers are not available or if the event delivery mechanism is unreliable.
Eventual Consistency: Ensuring eventual consistency across distributed components can be complex, as events are processed independently and may not reflect immediate updates to all parts of the system.
Debugging and Monitoring: Debugging and monitoring event-driven systems can be more challenging compared to request-driven systems, as the flow of events and their impact on system behavior may be less straightforward.
Complex Error Handling: Handling errors and ensuring fault tolerance in an event-driven architecture requires robust mechanisms for retrying failed events, managing dead-letter queues, and handling event processing failures.
Use Cases:
Real-Time Analytics: Processing events in real-time to derive insights and make data-driven decisions.
IoT Applications: Handling large volumes of sensor data and triggering actions based on events from IoT devices.
Decoupled Systems: Integrating disparate systems and services in a decoupled manner.
e-commerce
Conclusion:
Event-Driven Architecture offers significant advantages in terms of scalability, flexibility, and decoupling, making it suitable for modern, distributed systems. However, it also introduces complexities in managing event flows, ensuring consistency, and handling errors effectively. Organizations should carefully consider their specific requirements and trade-offs before adopting EDA to ensure it aligns with their architectural goals and operational needs.
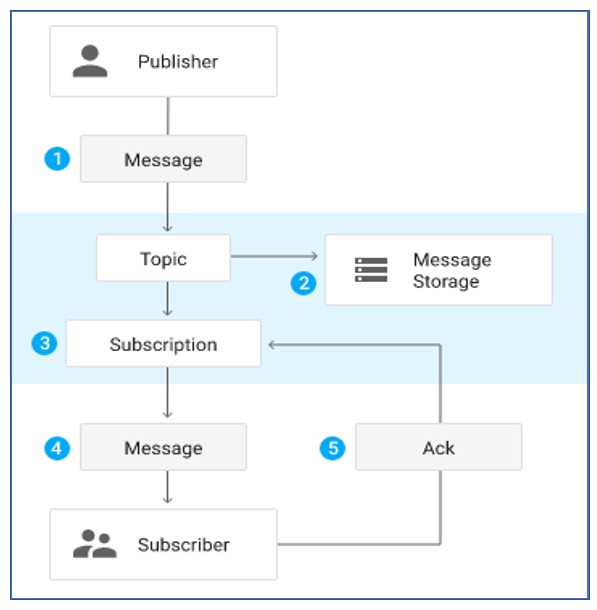
Pub-sub architecture operates on a messaging pattern where senders of messages (publishers) do not program the messages to be sent directly to specific receivers (subscribers). Instead, messages are categorized into topics or channels.
Subscribers express interest in one or more topics and receive messages related to those topics when they are published.
Key points:
Publishers publish messages to specific topics or channels without knowing who the subscribers are.
Subscribers subscribe to specific topics or channels of interest and receive messages from publishers on those topics.
Decoupling: This architecture decouples the sender (publisher) from the receiver (subscriber), allowing for flexibility and scalability.
Scalability: It supports scalable message distribution by allowing multiple subscribers to receive the same message without the publisher needing to send separate messages to each subscriber.
Asynchronous Communication: Messages are typically sent asynchronously, meaning publishers and subscribers do not need to be active at the same time.
Overall, pub-sub architecture facilitates flexible, scalable, and loosely coupled communication between components in distributed systems.
While pub-sub (publish-subscribe) architecture offers many benefits, such as scalability, decoupling, and flexibility, it also comes with several challenges that organizations need to consider:
Message Ordering: Ensuring strict message ordering across subscribers can be challenging, especially in asynchronous environments where messages may arrive out of order.
Complexity in Message Filtering: Managing large volumes of messages and efficiently filtering relevant messages for each subscriber can be complex, particularly in systems with numerous topics and subscribers.
Guaranteeing Delivery: Unlike point-to-point communication, where the sender can confirm delivery to the receiver, pub-sub systems may not provide built-in mechanisms to guarantee message delivery to all subscribers.
Scalability Concerns: While pub-sub systems are inherently scalable, managing large numbers of publishers and subscribers, as well as ensuring timely delivery of messages under heavy loads, can pose scalability challenges.
Handling Failure Scenarios: Dealing with failures, such as publisher or subscriber crashes, network partitions, or transient errors, requires robust error handling and recovery strategies to maintain system reliability.
Security and Access Control: Ensuring secure communication channels, authenticating publishers and subscribers, and implementing access control mechanisms to protect sensitive data can be more complex in a distributed pub-sub environment.
Monitoring and Management: Monitoring the health and performance of pub-sub systems, tracking message flow, and diagnosing issues across distributed components require comprehensive monitoring tools and management practices.
Complexity in Design and Maintenance: Designing and maintaining a pub-sub architecture, including choosing appropriate messaging protocols, handling schema evolution, and evolving the system as requirements change, can introduce complexity and require specialized expertise.
Addressing these challenges typically involves careful design, implementation of best practices, and leveraging advanced pub-sub features provided by messaging platforms and frameworks. Organizations must weigh the benefits against these challenges to determine if pub-sub architecture is suitable for their specific use cases and operational requirements.
Nowadays, we know that the use of microservices is widespread across various projects and companies. Among the many challenges this architectural model brings, one significant issue is managing data consistency in operations involving more than one service and potentially multiple databases.
Within this scenario of distributed systems and the need to handle transactional context, there's a pattern that fits perfectly: the SAGA Pattern.
Although many have heard of it, not everyone may fully grasp it. However, once understood, attempting to implement it can bring forth questions and challenges.
There's plenty of material available online about this pattern, but my aim here is to contribute in some way to your understanding.
Origin and concept Well, the original idea of SAGA actually emerged in 1987 through a paper by two computer scientists from Princeton University. Initially, the aim was to support transactions or long-lived operations, which they termed LLTs (Long Lived Transactions).
More recently, sagas have been applied to help solve consistency problems in modern distributed systems, as documented in a 2015 article on distributed sagas.
Since then, SAGA has evolved and has become well-suited for situations where you need to handle operations involving multiple microservices that require data consistency.
In a monolithic model, you perform a transaction in the database and save everything. In the microservices model, however, this transaction is "virtualized" because the operation itself consists of transactions that occur in each participating service.
The idea is simple: each microservice executes an operation altering its database. By the end of the process, all databases will be updated and consistent.
If a failure occurs during the execution of the process in any service, this process triggers compensatory actions to be executed in the services that operated beforehand.
It's worth noting here that for SAGA, conditional or partial failures don't matter.
Let me explain. If in an e-commerce system a failure occurs in the payment service due to the buyer's card being invalid or something similar, the system could still attempt to complete the transaction using other cards the customer may have registered on the platform or other available payment methods (here, I'm not discussing whether this functionality makes sense or not).
Only after all system attempts to complete the transaction are exhausted should it "notify" others to initiate compensatory actions. The SAGA pattern focuses on definitive success or definitive failure.
SAGA can also be seen as another name for eventual consistency. But in a way, it exposes the problem, in that we need to think about how to handle operations in your system if they don't succeed, which is where compensatory actions come into play.
So, if I were to summarize the pattern in an informal way in one sentence, I'd say it's basically a stack concept but with an "Undo (CTRL+Z)" functionality.
And obviously, whenever we talk about SAGA, we need to mention the two strategies for its implementation (Orchestration and Choreography).
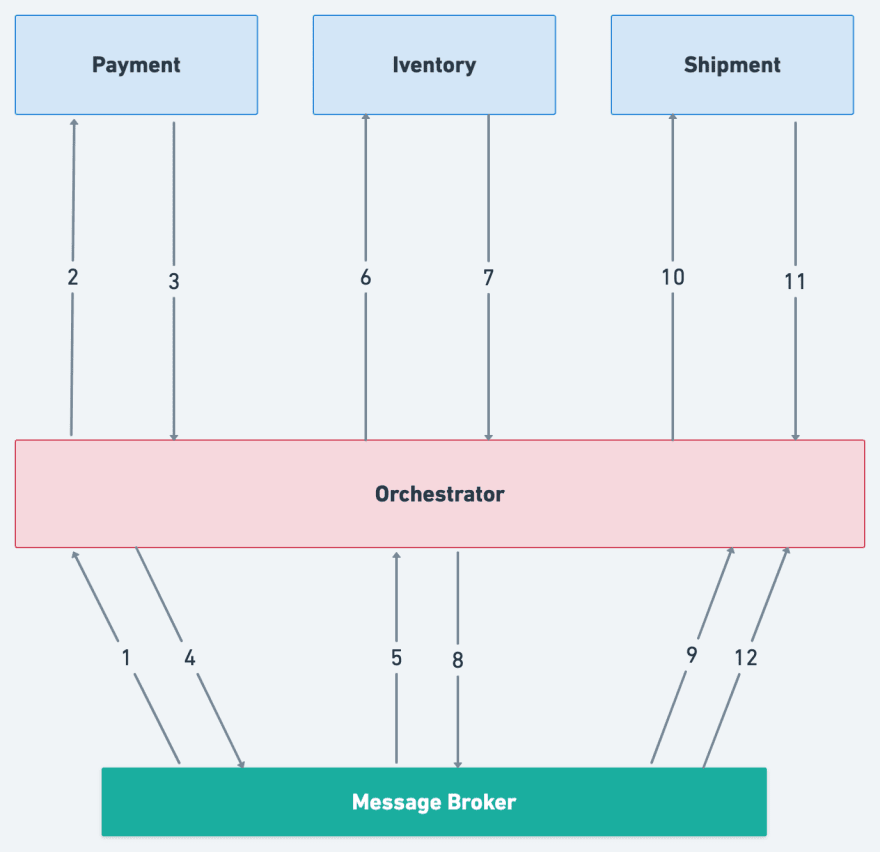
Orchestration In the orchestrated model, there's a central component responsible for triggering all services involved in a SAGA. If successful, the agent activates the next service. If it fails, this agent orchestrates compensatory actions. This component is also known as the Saga Execution Coordinator (SEC).
In this model, knowledge about the flow is removed from the microservices. Another component understands the flow and coordinates the operation's execution so that microservices focus solely on performing their operations.
Here, we shouldn't confine ourselves to synchronous communication strategies. It's quite common to use a Message Broker to support the flow, allowing services to be triggered upon receiving a message from a topic they are interested in and then posting back a new event as a result of their execution. This triggered event enables the orchestrator to activate the next process to be executed.
It's also worth noting that the orchestrator agent can be used as a kind of state machine for the various SAGAs that pass through it.